这章是用softmax的例子来回顾了ML的知识点。
softmax回归又叫多类逻辑回归,就是将输入数据进行分类,通过softmax函数得到每个类别的概率。
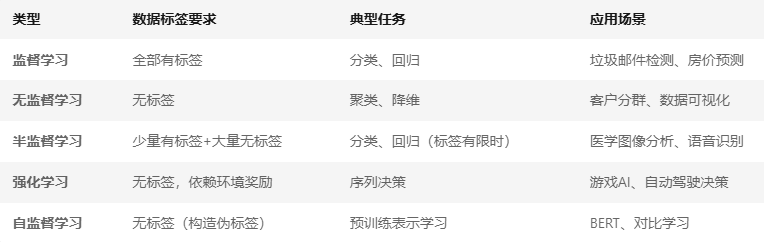
而这样的分类问题,是通过实现准备这样一个数据集:包含数据和数据对应的标签。让模型学习数据集和标签的对应关系,这样的过程叫做监督学习。
除了监督学习,还有
- 无监督学习
- 数据没有标签,模型从无标签数据中发现隐藏模式或结构。
- 如K-means、层次聚类、主成分分析(PCA)
- 半监督学习(Semi-Supervised Learning)
- 结合少量有标签数据和大量无标签数据训练模型。
- 适用于标注成本高,但未标注数据丰富(如医学图像分析)。
- 强化学习(Reinforcement Learning, RL)
- 模型通过与环境交互,根据奖励信号调整策略,目标是最大化长期累积奖励。
- 适用于序列决策问题(如机器人控制、游戏AI)。
- Q-learning、深度强化学习(DQN)、策略梯度(PPO)。
- 自监督学习(Self-Supervised Learning)
- 通过构造“伪标签”从无标签数据中学习,属于无监督学习的子类。
- NLP中的预训练模型(如BERT通过掩码预测学习上下文)。
- 图像中的对比学习(如SimCLR通过图像增强构造正负样本对)。
- 多任务学习(Multi-Task Learning)
- 同时学习多个相关任务,共享部分模型参数以提高泛化能力。
- 一个模型同时完成文本分类和实体识别。
无论是怎么样的机器学习,都一定会包含三个要素
- hypothesis class,也就是模型的结构
- loss函数
- 优化方法
比如k分类问题,输入数字的图像,输出的是每个数字的一种可能性(这里还不能说是概率,因为不满足概率的条件)
为什么要用矩阵:数学上更严谨,同时有利于并行计算提高效率。
loss函数是为了对比输出的结果和原本标签之间的差距。一个最简单的loss函数:
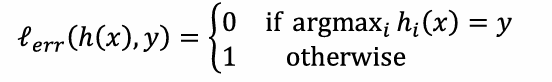
但是这个函数并不好,因为不可导。
进一步我们把上面提到的输出的可能性转化为概率,而这一步就是softmax函数:
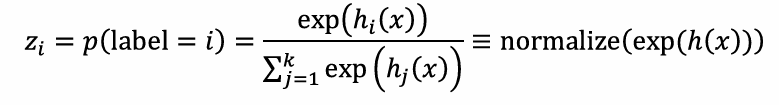
其中
根据这个转化后的概率,可以进一步得到loss的计算公式,也就是softmax loss或者叫做交叉熵损失。
为什么要用负对数?

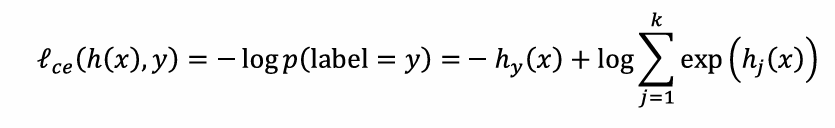
其中
目前常用的优化方法是SGD,就是随机梯度下降,因为如果对全体对象进行梯度下降,空间太大了。SGD是进行多轮,每次抽取一定样本来进行更新。

